
这次准备开启一个新的系列来写了,聊聊分布式系统中的关注点。节奏不会排的太紧凑,计划两周一更吧,中间穿插着输出一些产品、运营、以及个人的深度思考。欢迎大家奔走相告~
本文是本系列的第二篇。是前一篇《分布式系统关注点——数据一致性(上篇)》的后续内容。
前一篇可能讲的过于通俗,逼格不高,不太受大家待见。。本篇会继续坚持尽量讲的通俗易懂,坚信让更多的人看懂才有更大的价值。不过相对来说内容的专业度有所上升。
已经对数据一致性问题做了一次剖析,那么怎么解决由于故障导致的不一致问题呢?本文会围绕“共识”这个点展开。
01
一致性问题其实是一个「结果」,本质是由于数据冗余导致的,如果没有冗余,也就不会有一致性问题了。
分布式系统里的各个子系统之间之所以能够相互协作,就是因为其之间冗余了相同的数据作为“信物”,要不然我都不认识你的话,为什么要配合你干活呢。所以这个“信物”变了,你得通知我,要不然我又不认识你了。这个“信物”变更达成一致性的过程称作达成「共识」。所以:
一致性问题是结果,共识是为达到这个结果所要经过的过程,或者说一种手段。
在分布式系统中,冗余数据的场景不限于此,因为规模越大的系统,越不能容忍某一个子系统出问题后产生蝴蝶效应,所以往往会做高可用。小明1号倒下了还有千千万万个小明X号在坚守岗位,理想中的全天候24小时提供服务~。高可用的本质是通过相同数据存储多个副本,并都可对外提供服务。比如每个小明X号都有一本《按摩指法白皮书》,谁请假了都可以由其它小明X号提供相同的按摩服务。但是这个本《按摩指法白皮书》改了,就得通知到每个人,因为这是服务的全部和来源,所以在做了高可用的集群中数据冗余的问题更为突出。
实际上,如果分布式系统中各个节点都能保证瞬时响应、无故障运行,则达成共识很容易。就好像我们人一样,在一定范围内只要吼一嗓子,通过稳定的空气传播,相关人是否接收到这个消息,并且给出响应几乎可以是“瞬时”的。但是正如〖上篇,👈点我〗文中提到,这样的系统只停留在想象中,响应请求往往存在延时,网络会发生中断,节点发生故障,甚至存在恶意节点故意要破坏系统。这就衍生出了经典的「拜占庭将军问题」[1]。
02
我们一般把「拜占庭将军问题」分为2种情况来看待:
- 拜占庭错误。表示通过伪造信息进行恶意响应产生的错误。
- 非拜占庭错误。没有进行响应产生的错误。
这个问题的核心在于:
如何解决某个变更在分布式网络中得到一致的执行结果,是被参与多方都承认的,同时这个信息是被确定的,不可推翻的。
好比如何让所有的小明X号收到的都是《按摩指法白皮书Ⅱ》,而不是其它的,并且把原来的那本销毁掉。这个问题衍生出了很多“共识”算法,解决「拜占庭错误」的称作Byzantine Fault Tolerance(BFT)类算法,解决「非拜占庭错误」的称作Crash Fault Tolerance(CFT)类算法。从这个2个名字中也可以看出,本质的工作就是「容错」。有的小伙伴在平时的工作中可能对「容错」的重要性感知没那么强烈,不就产生一个BUG或者异常数据么,但是在航天领域,一个小错误可能导致整个发射的失败,代价非常巨大。
对「拜占庭将军问题」想深入的了解的,可以自行查阅相关资料,这里就不展开了,文末附上提出时的论文。
我们常见的软件开发中一般不会考虑「拜占庭错误」,但它是区块链项目的必需品。不过在主流的分布式数据库中,皆能看到「非拜占庭错误」的身影,诸如Tidb的Raft 算法,CockroachDB的Raft算法。虽然我们大家在日常的coding中,对数据库底层原理的了解并不是必须项。但是只要当我们涉及到应用程序级别的高可用时,那么至少「非拜占庭错误」是必须要面临的一道坎。
03
BFT类型算法又有2个分支。「基于确定性的」和「基于概率的」。
先聊聊「基于确定性的」,此类算法表示一旦对某个结果达成共识就不可逆转,即共识是最终结果。它的代表作是PBFT(Practical Byzantine Fault Tolerance)算法[2],自从有了央行背书(区块链数字票据交易平台),名声更大了。算法的原理,如下图:
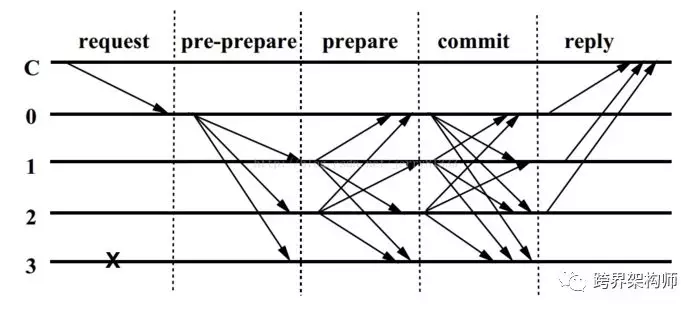
▲图片来源于网络,版权归原作者所有
拿军队来比喻,这里的直线C可以认为是“总司令”,直线0是“军长”,直线1、直线2、直线3都是“师长”,值得注意的是3号师长叛变了。整个过程这样解释:
-
「request」:总司令给军长下了一个命令,“干!”。
-
「pre-prepare」:军长把命令又广播给3个师长。
-
「prepare」:每个师长收到并同意之后将发送“收到”给军长和其他两个师长。
-
「commit」:每个师长收到2f个师长(军长不做prepare)的“收到”请求后发送“随时开干”给军长和其他两个师长。(f为可容忍的拜占庭节点数)
-
「reply」:每个师长收到2f+1条“随时开干”消息之后,就能认为总司令的命令在相关的师长中都到达了“随时开干”的状态,那么他就直接开炮了!
真正深入了解PBFT的话还有很多内容,这里就不继续展开了,有兴趣的小伙伴自行查阅文末论文地址或者直接后台回复“一致性”打包下载。
再聊聊「基于概率的」,此类算法的共识结果则是临时的,随着时间推移或某种强化,共识结果被推翻的概率越来越小,成为事实上的最终结果。它的代表作是PoW(Proof of Work)算法,曾经高达2W美元/个的比特币就是基于这个算法来实现的。算法的原理拿“修仙”来做个简单的比喻(实际比特中的算法比这更复杂):
-
自己努力修炼,并让神仙中大于一半的人认可你的修为,同意你成仙。
-
随之你就成为了神仙。并且参与到评判后续其他人是否可以成为“神仙”的事情中去。
-
这个事情如果想通过贿赂来达到的话,随着这个团队的人数越多,贿赂的成本越大,就可以认为去做贿赂的人越少,那么导致被误判的概率就越低,最终就越可信。
被误判的概率公式是: 0.5 ^ 个数,如果个数=6的话,误判的概率是1.5625%。如果个数=10的话,就已经是0.09765625%了,指数级下降。
值得注意的是,「基于确定性的」和「基于概率的」对于不合作节点的标准是不同的,前者至多能容忍1/3,后者是小于1/2。
04
正如上面所说CFT类算法解决的是分布式系统中存在故障,但不存在恶意节点的场景(即可能消息丢失或重复,但无错误消息)下的共识达成问题。「拜占庭将军问题」的提出者Leslie Lamport也在他另外的论文[3]中提出过「Paxos问题」,与这相似。在论文中通过一个故事类比了这个问题,如下:
希腊岛屿Paxon 上的「执法者」在「议会大厅」中表决通过『法律』,并通过「服务员」传递纸条的方式交流信息,每个「执法者」会将通过的『法律』记录在自己的「账目」上。问题在于「执法者」和「服务员」都不可靠,他们随时会因为各种事情离开「议会大厅」,并随时可能有新的「执法者」进入「议会大厅」进行法律表决。
使用何种方式能够使得这个表决过程正常进行,且通过的『法律』不发生矛盾。
—— 百度百科
这里的关键对象在我们的系统中,可以类比为:
- 议会大厅 = 分布式系统
- 执法者 = 某个程序
- 服务员 = RPC通道
- 账目 = 数据库
- 法律 = 一次变更操作
Leslie Lamport自己也提出了解决这个问题的算法,「Paxos」算法[4]。这个算法的关键由以下3个定义来体现:
- 每次“变更”都有个唯一的序号,并且能够通过它识别新旧
- 「执法者」只能接受比已知的“变更”更新的变更
- 任意两次“变更”必须有相同的「执法者」参与
这3点仅仅是保证一致性的最关键部分,全部内容还有很多。有兴趣的小伙伴自行查阅文末论文地址或者直接后台回复“一致性”打包下载。
「Paxos」算法是一种无领导人(Leaderless)算法,实现比较复杂,所以产生了很多变种来简化它,其中名气最大的应该是「Raft」,2013年才问世。「Raft」算法是一种领导人(Leadership)的算法。由以下2个过程保证达成共识:
- 只会存在一个活着的领导人,领导人负责跟随者的数据同步。
- 如果领导人“失联”了,那么每个跟随者都可成为候选人,最终比较谁的term最新,谁就是新的领导人。这个term是每个节点内部维护的一个自增数。
虽然跟随者的投票秉承先到先得,但是还是会遇到多个term相同的候选人获得了相同票数(简称「分割投票问题」),那么进行新一轮投票,直到决出胜负为止。由于Raft用随机定时器来自增term,加上网络是不稳定的,所以再次遇到相同票数的概率就大大降低了。
完整的过程更复杂一些,有一个Raft算法的动画推荐给大家,有兴趣的可以了解一下:http://thesecretlivesofdata.com/raft/。
题外话,大家经常用的Zookeeper里的「ZAB」(ZooKeeper Atomic Broadcast)算法也是CFT类算法,是以Fast Paxos算法为基础实现的。
05
回过头来看,我们发现,想要更严谨的一致性,那么就需要增加相互通讯确认的次数,但是这会导致性能低下,正如PBFT和Paxos一样。但是分布式系统就是这样,到处都需要Balance,找到最适合的才是最重要的。
聊完了数据层面的「共识」问题,我们下回再聊聊「分布式事务」的问题,围绕着常见的CAP、BASE理论展开。
最后如果说想成为数据一致性专家,问有没有捷径的话。去阅读老爷子Leslie Lamport的论文就是捷径,他的个人主页:http://www.lamport.org/ 。
▶ 后台回复“一致性”关键字,可打包下载哟~
[1]《The Byzantine Generals Problem, ACM Transactions on Programming Languages and Systems》,Leslie Lamport,1982。
链接:https://www.microsoft.com/en-us/research/uploads/prod/2016/12/The-Byzantine-Generals-Problem.pdf
[2]《Practical Byzantine Fault Tolerance》,Miguel Castro&Barbara Liskov,1999。
链接:http://101.96.10.63/pmg.csail.mit.edu/papers/osdi99.pdf
[3]《The Part-Time Parliament》,Leslie Lamport,1998。
链接:https://www.microsoft.com/en-us/research/uploads/prod/2016/12/The-Part-Time-Parliament.pdf
[4]《In Search of an Understandable Consensus Algorithm》,Diego Ongaro&John Ousterhout,2013
链接:https://raft.github.io/raft.pdf
原创文章,转载请注明本文链接: https://zacharyfan.com/archives/370.html
关于作者:张帆(Zachary,个人微信号:Zachary-ZF)。坚持用心打磨每一篇高质量原创。欢迎扫描二维码~
定期发表原创内容:架构设计丨分布式系统丨产品丨运营丨一些思考。
如果你是初级程序员,想提升但不知道如何下手。又或者做程序员多年,陷入了一些瓶颈想拓宽一下视野。欢迎关注我的公众号「跨界架构师」,回复「技术」,送你一份我长期收集和整理的思维导图。
如果你是运营,面对不断变化的市场束手无策。又或者想了解主流的运营策略,以丰富自己的“仓库”。欢迎关注我的公众号「跨界架构师」,回复「运营」,送你一份我长期收集和整理的思维导图。
